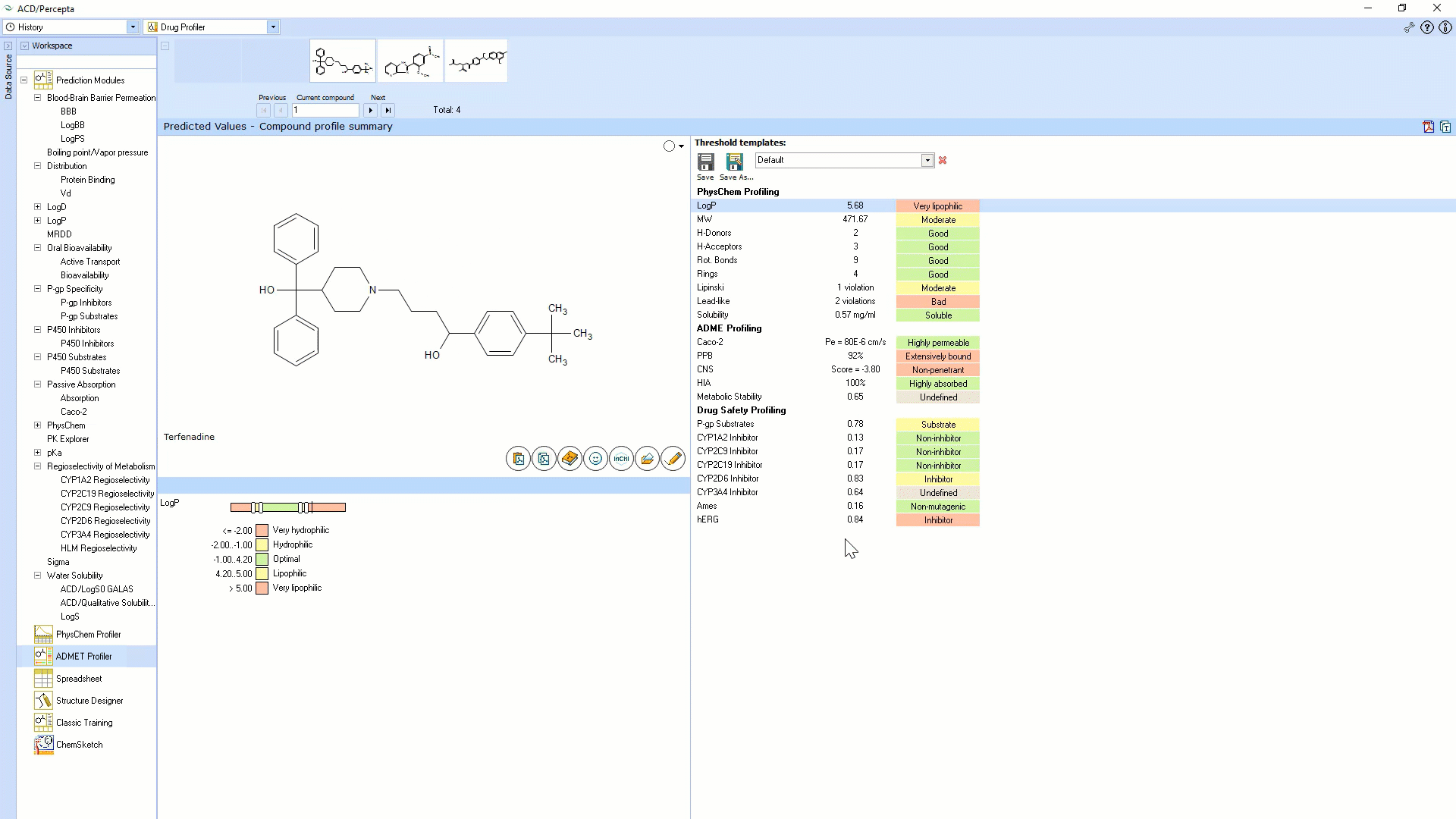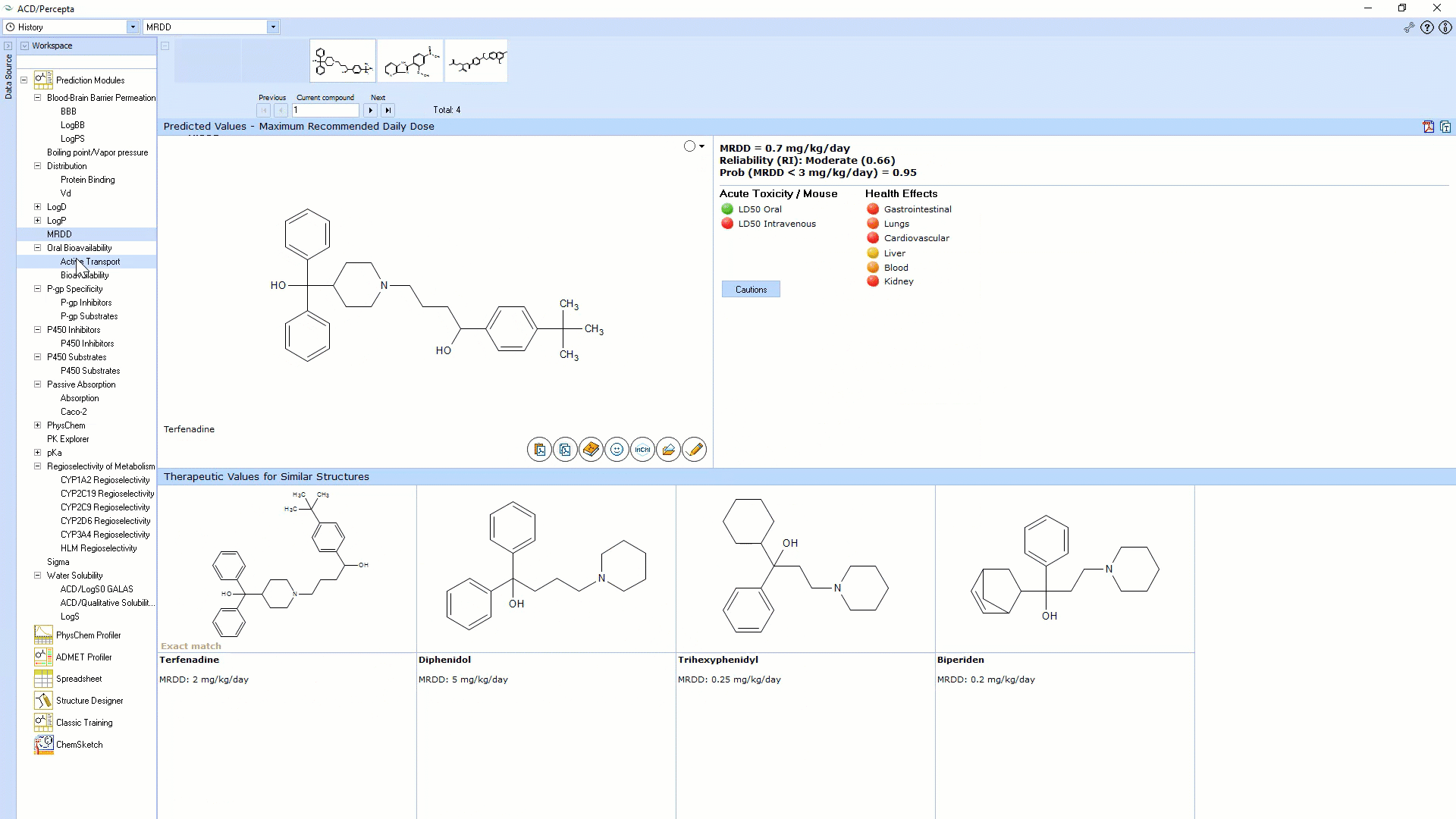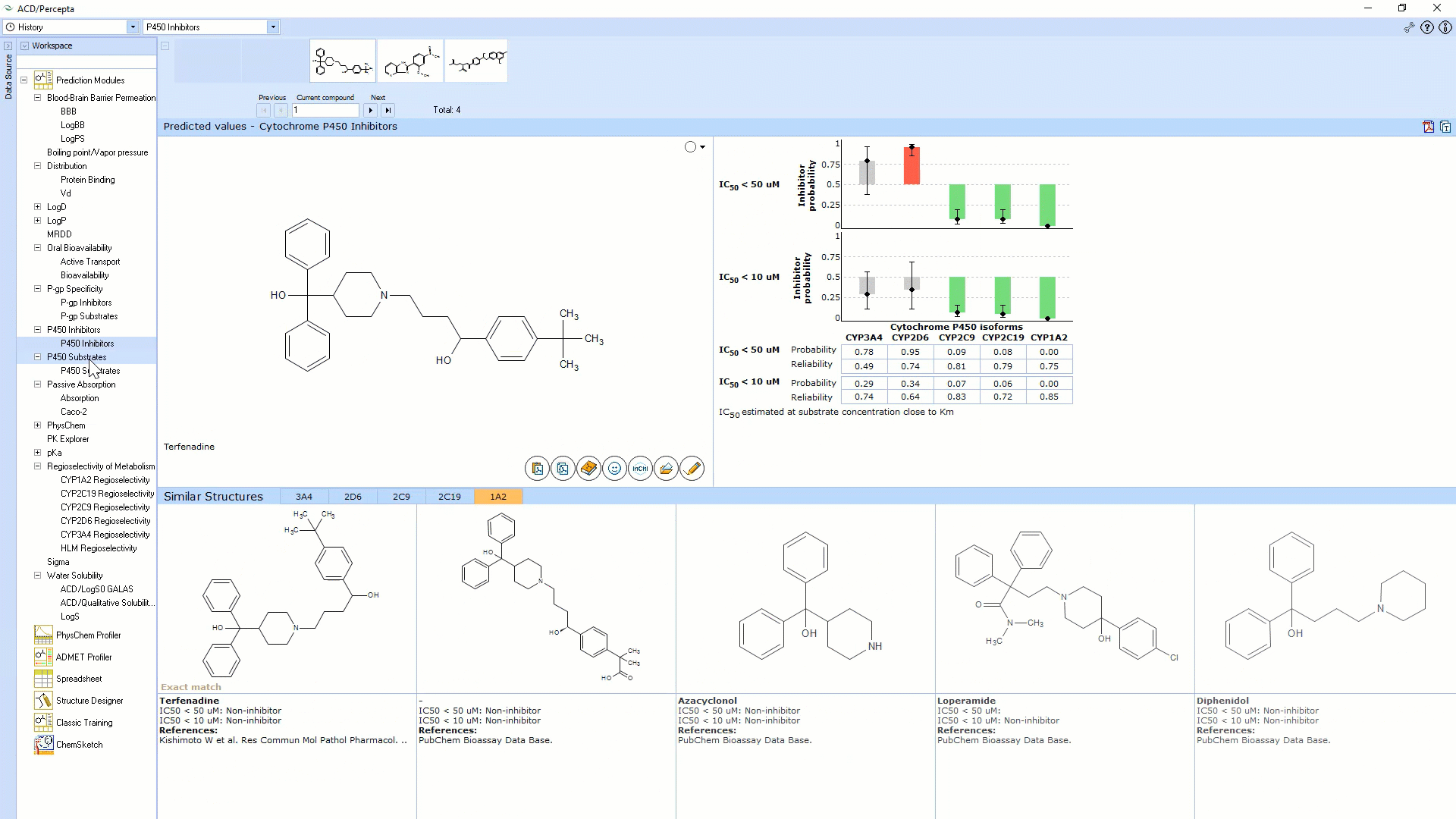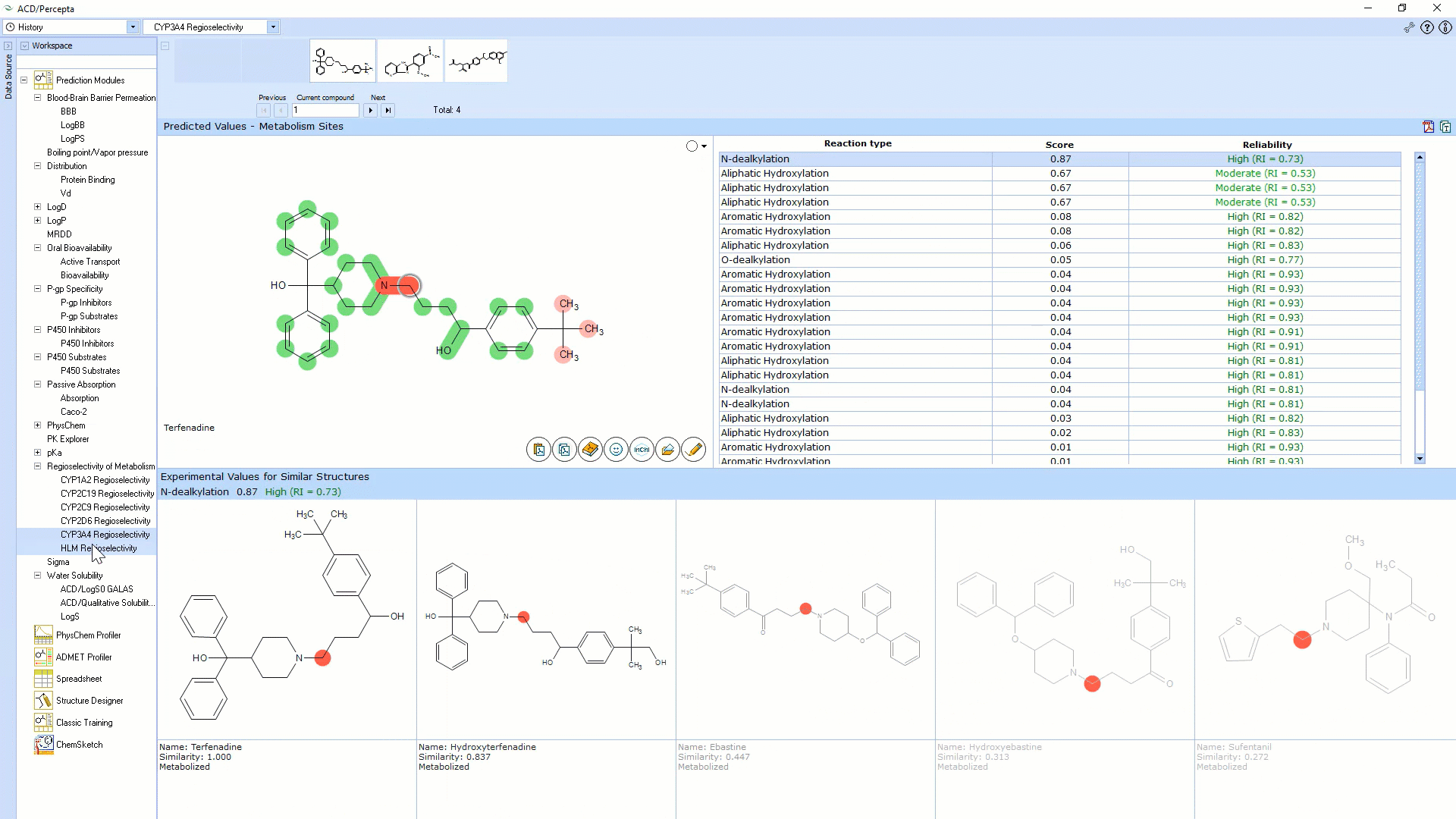
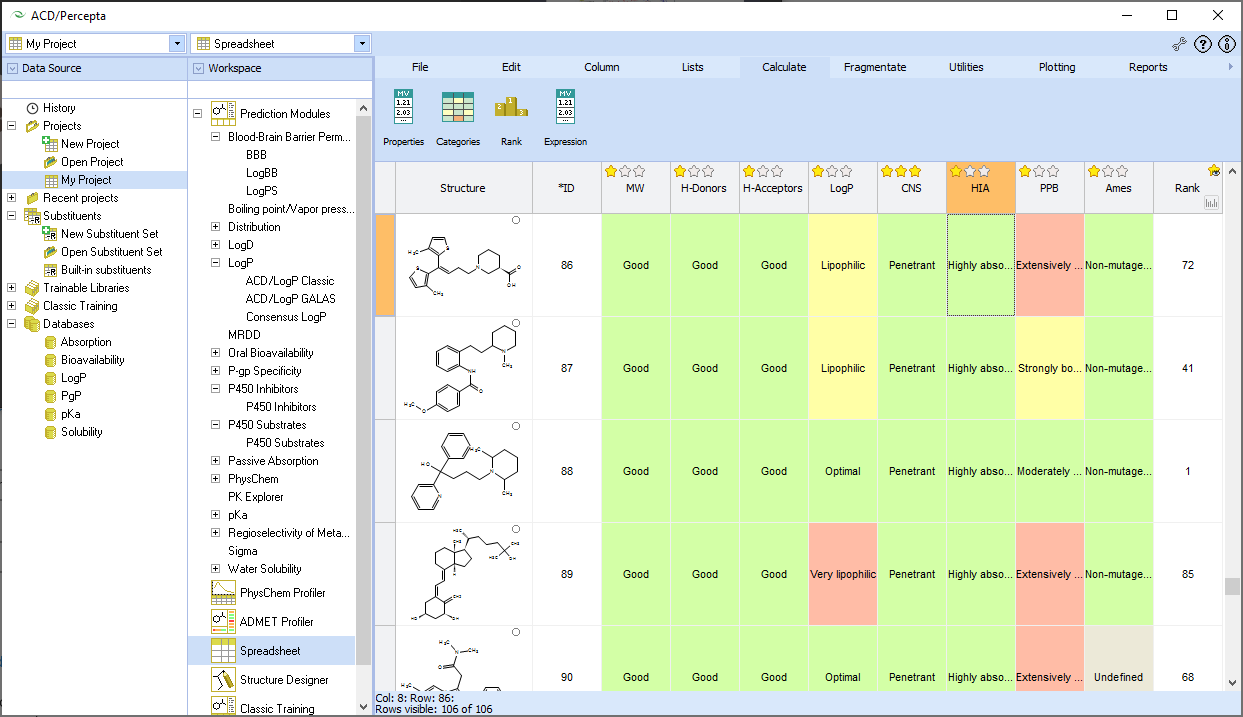
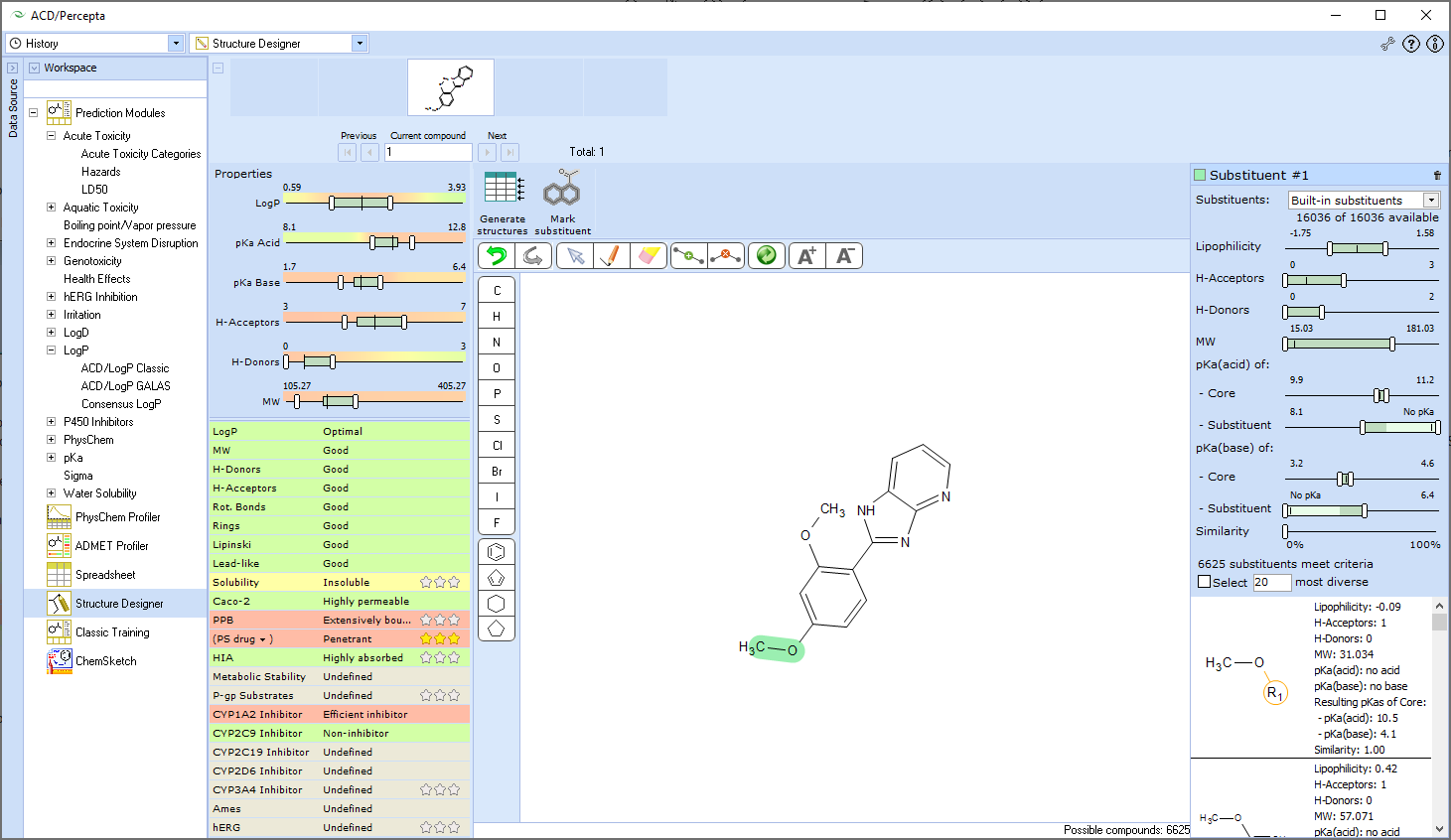
计算模拟预测目标物的吸收,分布,代谢和排泄(ADME)特性,支持对库的高通量筛选,提供对药理作用的深入了解,有助于确保产品对人类的使用是安全的.
ADME Suite可提供基于结构的高质量药物动力学特性计算。
- 基于结构预测
- 血脑屏障透过性
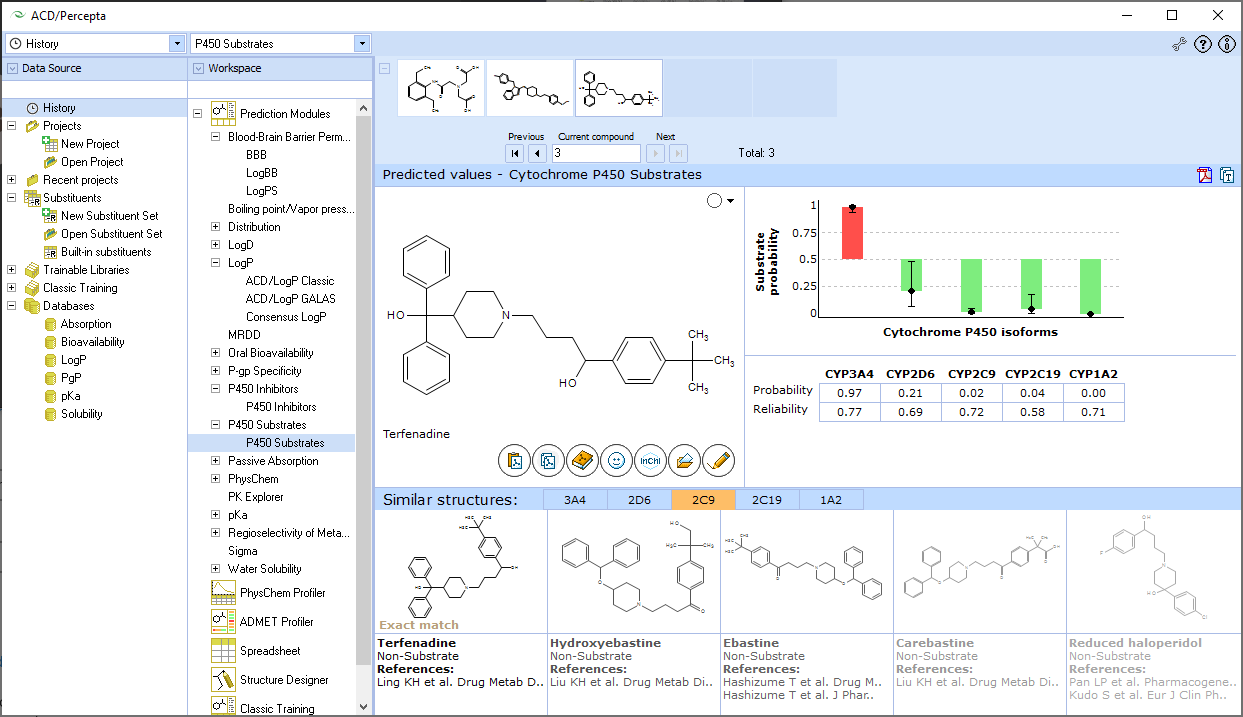
- 细胞色素P450*酶系的抑制性和底物特异性
- 分布*
- 临床实验推荐日最大剂量
- 口服生物利用度-基于logP以及剂量
- 被动吸收
- P-糖蛋白特异性结合
- 理化性质- logP,* logD,* pKa,* 水溶性,* 等.
- 代谢位点
- 提供预测置信度评估
- 搜索对应模型的内部数据库的实验数据
- 用实验数据训练预测模型,以更好地反映新的化学空间
- 包含自定义模型和自定义预测算法
*表示这些模型支持自添加数据训练